Domain Theory Development Environment
Current domain theories range between 300 and 1,600 axiom-equivalents. Creating domain theories that exceed 10,000 axiom-equivalents will require new software tools. We propose to build a domain theory development environment that drastically simplifies the process of creating domain theories. This environment will have three key features: (1) Multi-modal editing facilities, combining textual and graphical knowledge entry methods, (2) Integrated reasoning facilities and example libraries for incremental testing, and (3) a modular, lightweight architecture, relying heavily on COTS components, that can operate both in networked environments and in the field. We describe each feature in turn.
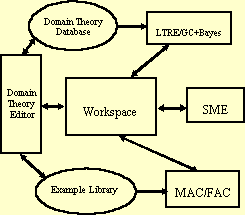
Architecture for the Domain
Theory Development Environment,
illustrating the integration of our problem-solving tools
Multi-modal editing facilities: Our tools will provide supportive editing facilities for domain theory constructs at the level of predicates and axioms and also in terms of larger constructs, including model fragments , plan operators, and schemas. Special emphasis will be placed on facilities to support the compositional modeling methodology. It will include visualization tools for browsing hierarchies, clauses, and lattices of modeling assumptions. The sketching facilities being developed will be fully integrated.
Integrated reasoning facilities and example libraries: We believe that testing is a critical aspect of validating domain theories. Integrated reasoning capabilities will be provided for incremental testing, including model formulation algorithms, qualitative reasoning, and the analogical processing systems being developed. A key feature of these algorithms is that they are designed to operate efficiently and incrementally. Our main inference engine, based on a logic-based TMS, incorporates fact garbage collection and simple Bayesian evidence combination strategies to efficiently generate plausible interpretations of situations without combinatorial search. Our new qualitative reasoning algorithms are built upon this substrate. While envisioning facilities will be provided for occasional off-line analyses, they are not the central focus of our qualitative reasoning work anymore. Instead, we provide fundamental operations (e.g., model formulation, state completion, limit analysis) that can be combined with task-dependent control strategies to provide focused qualitative reasoning services.
An Example Library provides a database of problems and situations that serve as benchmarks for domain theory development. The best domain theory development efforts use such examples regularly. We want to provide software support for this practice. Elements in the Example Library are described informally, using text, images, or whatever form of media is appropriate. Analyses of these examples using the evolving constructs of the domain theory are also stored with them, providing a mechanism for tracking progress and change management. Case libraries for particular purposes can be generated by extracting subsets of the example library analyses. Such libraries will be used for testing MAC/FAC and running retrieval experiments.
Lightweight architecture relying on COTS components: An environment that can be distributed at low cost and used for many tasks without special-purpose hardware would cut the cost of creating domain theories, and widen the pool of experts who can be involved. Ideally, we would like to make such environments free to the academic community, to leverage the same public-spirited energies that have created a wealth of publicly available software. This requires using COTS components where possible. For instance, we will use standard relational databases to provide the persistent store needed for the knowledge bases and case libraries. Such databases can be harnessed to store knowledge bases with reasonable performance, and existing protocols in the commercial software community (e.g., ODBC and its progeny) to promote vendor independence. Ideally, a special-purpose persistent object database would be better, but the licensing fees for such databases would substantially limit how freely we could distribute our environment. Developing our own object database layer would distract from focusing on what we are uniquely qualified to do. On the other hand, it is hard to buy a computer from a reputable vendor anymore without it coming with an ODBC-compliant database product pre-installed. Similarly, we will ride the curve of technology improvements in VRML plug-ins for web browsers, rather than trying to build our own viewers. We will use a commercial implementation of Common Lisp for "glue" and for implementing the editing facilities and our problem-solving tools. In addition to providing an efficient and flexible platform, it can be used to create royalty-free executables, which will enable this software to be more widely distributed than it could be otherwise.
The architecture we have outlined should provide reasonable performance for medium-scale examples on high-end notebook computers. In better-equipped environments, extra hardware support could provide substantial speedups. Computers with 32MB of RAM are showing up as standard items in discount stores now; for high-end machines 128MB of RAM or more is quite feasible. Today's COTS databases provide network facilities, so that a small workgroup could share a common Domain Theory Database and Example Library. DSP cards or symmetric multiprocessing could be added to accelerate similarity-based retrieval. By riding the commercial software and hardware trends, we should be able to create a domain theory development environment that scales in capabilities as a natural consequence of market technologies.
Back to HPKB page | Back to Sketching page | Back to QRG Home Page